Spécifications techniques
Spécifications de la solution retenue et des implications pratiques
Page suivante : Implémentation
Attention : cette page contient des formules en LaTeX qui ne sont pas correctement supportées sur le site web, pour une meilleure expérience veuillez consultez la page sur Github.
Sommaire
- Spécifications techniques
Terminologie
Appareil : Périphérique avec lequel interagit l’utilisateur pour accéder, entre autres, au gestionnaire de mots de passe
Client : Application assurant la communication avec le serveur depuis un appareil de l’utilisateur, désigne autant les applications mobiles, web ou en ligne de commande, officielles ou d’implémentation autre
Serveur : Périphérique de communication centralisé assurant le stockage jusqu’à la distribution des messages sur tous les appareils, désigne autant l’implémentation officielle ou autre, le serveur est considéré unique, les problématiques de résolution d’adresse ou de balance de charge ne sont pas prises en compte
Coffre : Ensemble de mots de passe stockés et de secrets à l’intérieur d’un client et partagé avec d’autres appareils, chaque client peut posséder plusieurs coffres qui ne sont pas nécessairement partagés avec les mêmes appareils
Initialisation du coffre
Avant de pouvoir contenir les secrets d’un utilisateur, un coffre doit être initialisé. Cette initialisation comprend deux parties : l’enregistrement de chaque client auprès d’un serveur pour assurer la livraison des futurs messages et le partage des informations entre les clients pour se découvrir mutuellement.
Enregistrement sur le serveur
Tout utilisateur qui souhaite communiquer avec le serveur doit au préalable s’être enregistré auprès de celui-ci. Le but est de limiter la surface d’attaque sur le serveur : toute communication qui ne sera pas émise depuis un appareil enregistré sera refusée par le serveur.
Sur chacun de ses appareils, l’utilisateur doit enregistrer le client auprès du serveur. L’enregistrement vaut pour un seul coffre à l’intérieur d’un seul client depuis un seul appareil. Si l’utilisateur ajoute un autre coffre sur un de ses clients, il doit de nouveau procéder à l’enregistrement depuis son appareil. L’utilisateur peut enregistrer en une seule fois plusieurs coffres auprès du serveur, les demandes d’enregistrement sont alors envoyées en parallèle au serveur, mais un seul challenge lui sera demandé pour valider l’ajout de tous les coffres.
Du point de vue du serveur, chaque demande d’enregistrement est composée d’un identifiant utilisateur, de la clé publique du client et d’un identifiant de coffre mis bout à bout, ce qui forme l’identifiant d’enregistrement user_id:client_public_key:vault_id. L’identifiant d’enregistrement sera utilisé aussi bien pour vérifier que les messages entrants proviennent d’un appareil enregistré que pour vérifier que les appareils destinataires de ce message sont également tous enregistrés.
L’identifiant de l’utilisateur user_id doit permettre de contacter l’utilisateur via un service tiers afin de s’assurer de son identité, comme une adresse email ou un numéro de téléphone portable. L’adresse email offre l’avantage de la gratuité d’envoi des mail pour le serveur, vis-à-vis du numéro de téléphone qui offre une meilleure vérification de l’identité de l’utilisateur (il est moins facile de multiplier les numéros de téléphone que les adresses email) mais qui nécessite de passer par un tiers payant pour envoyer des SMS. Pendant le développement, l’identifiant utilisateur sera une adresse email, à termes cela pourra évoluer vers un numéro de téléphone.
La clé publique du client client_public_key est créée lors de l’installation de client ou lors de la création du coffre. La clé publique servira d’identifiant pour les appareils avec lesquels le coffre est partagé et sera utilisée pour le calcul de la clé partagée entre les clients. La clé publique d’un client peut être différente pour différents coffres.
Du point de vue du serveur, la clé publique d’un client est un identifiant secret. L’utilisateur ne doit pas dévoiler ses clés publiques. La raison pour utiliser une clé publique plutôt qu’un identifiant est de pouvoir échanger cette clé avec ses autres clients pour calculer un secret partagé.
L’identifiant du coffre vault_id est un code aléatoire de quelques chiffres généré lors de la création du coffre à l’intérieur d’un client. Lorsque l’utilisateur souhaite ajouter un coffre sur autre autre appareil, il doit recopier cet identifiant depuis un client qui possède déjà ce coffre. Le premier intérêt de cet identifiant est de fournir une sécurité supplémentaire empêchant un utilisateur malveillant de se faire passer pour un utilisateur déjà enregistré en connaissant son identifiant et sa clé publique. L’utilisateur ne peut pas surcharger le serveur de messages s’il ne connaît pas également l’identifiant du coffre. Cet identifiant permet également aux utilisateurs de posséder plusieurs coffres dans un client qui peuvent être chacun partagés avec des appareils différents.
Selon la fréquence et les moyens déployés par les attaquants pour tenter de remplir la pile de messages en attente avec des messages frauduleux, il est possible de changer la taille de l’identifiant du coffre de quelques chiffres à 128, 256 ou 512 bits. La recopie de l’identifiant du coffre entre les appareils ne sera alors plus faite manuellement par l’utilisateur, mais via une autre solution de communication comme le Bluetooth, le QR Code ou le protocole ICE directement intégrés à l’application.
Afin de préserver l’anonymat lors des futures requêtes, le serveur n’enregistrera que l’identifiant d’enregistrement mais son hachage cryptographique, de la manière suivante : hash( hash(user_id) + hash(client_public_key) + hash(vault_id)). Ainsi, lorsqu’un client communiquera plus tard avec le serveur, il pourra lui fournir uniquement le hachage de son identifiant utilisateur, sa clé publique et le hachage du coffre, et le serveur pourra confirmer que ce client est bien enregistré sans connaître son identité ou savoir à quel coffre il accède.
Le calcul du hachage de l’identifiant d’enregistrement par la concaténation des hachages des trois parties servira pour que le serveur puisse manipuler les identifiants sans être capable de retracer l’identité de l’utilisateur.
Séquence d’enregistrement
L’utilisateur envoie une requête d’enregistrement au serveur depuis un client avec l’identifiant d’enregistrement user_id:client_public_key:vault_id. Le serveur envoie un challenge, c’est-à-dire un code à usage unique, via email ou SMS grâce à l’identifiant utilisateur, puis répond au client que le challenge a été envoyé. L’utilisateur doit saisir le code dans le client qui va l’envoyer au serveur. Le serveur ajoute ensuite l’utilisateur dans un filtre de Bloom et répond une confirmation d’enregistrement au client. La communication peut se terminer.
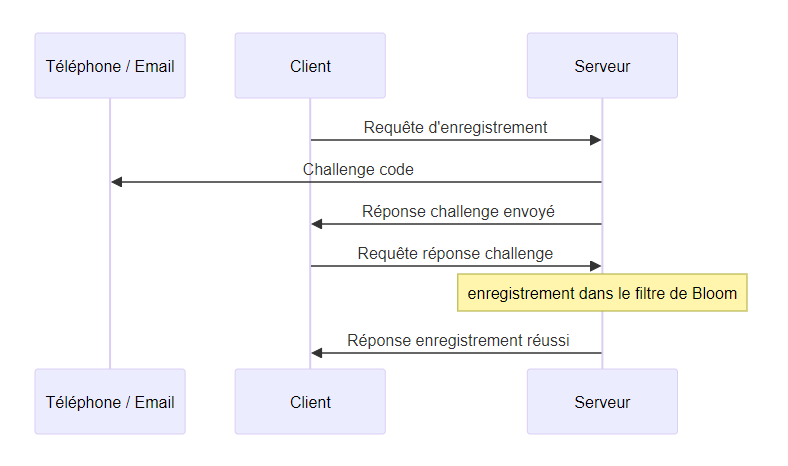
À l’issu de l’enregistrement, le coffre n’est pas encore partagé entre les appareils. Plus spécifiquement, les clients qui doivent se partager le coffre ne se connaissent pas encore.
Fonctionnement du filtre de Bloom
Le filtre de Bloom est une structure de données atypique par son aspect probabiliste. Le filtre de Bloom ne supporte que deux opéarions : l’écriture d’une nouvelle entrée dans la structure et le test de présence d’une entrée. Il n’est pas possible de stocker des données dans cette structure, c’est pourquoi on parle de filtre.
Soit $T$ un tableau de bits de taille $m$ dont toutes les cases sont initiées à 0 et $h$ une famille de $k$ fonctions de hachage cryptographique notées $h_k$ de taille $m$ bits. Donc pour tout $i$ entre 0 et $m$ et pour tout entrée $e$, la sortie de $h_i$ sur $e$ est comprise entre 1 et $m$, ce qui correspond à une case du tableau $T$. On suppose que les fonctions de hachage $h_i$ ont été choisies afin de garantir une répartition statistiquement uniforme entre 1 et $m$.
Pour ajouter un élément dans la structure, il faut calculer successivement les $h_i$ sur cet élément pour $i$ allant de 1 à $m$ et affecter les cases correspondantes à la valeur 1.
Fonction ajout_filtre(e)
Pour i de 1 à m
T[hi(e)] = 1
Fin Pour
Fin Fonction
Pour tester la présence d’un élément, il faut calculer les $h_i$ sur cet élément et vérifier que toutes les cases correspondantes ont la valeur 1. Si au moins une case est à la valeur 0, alors l’élément n’est pas présent.
Fonction test_filtre(e)
Pour i de 1 à m
Si T[hi(e)] = 0 alors
Retourner Faux
Fin Si
Fin Pour
Retourner Vrai
Fin Fonction
Après avoir ajouté de nombreux éléments dans la structure, il est probable que lors de l’ajout d’un nouvel élément $e$ au moins l’une des fonctions $h_i$ évaluée sur $e$ renvoie vers une case du tableau $T$ qui ait déjà la valeur 1, c’est une collision. Cela signifie que lors de l’ajout d’un élément antérieur $e’$, il y avait une fonction $h_j$ qui renvoyait la même case, soit $h_i(e)=h_j(e’)$. Ce n’est pas un problème, même si plusieurs collisions se produisent lors de l’ajout d’un seul élément, puisque lors d’un test de présence il faut vérifier que tous les $h_i$ sont non nuls.
À cause de ces collisions, il n’est pas possible de retirer un élément du filtre de Bloom. Si on affectait les cases correspondantes aux $h_i(e)$ à 0, il ne serait pas impossible qu’au moins l’une de ces cases présente une collision avec un autre élément $e’$. Un test de présence sur cet élément $e’$ après la suppression de $e$ renverrait alors Faux alors que l’élément $e’$ avait bien été ajouté.
Il existe une probabilité non nulle que lors du test de présence d’un élément $e$, chacune des $k$ fonctions $h_i$ aient une collision, le test renverra alors que l’élément $e$ est présent alors qu’il n’a pas été ajouté : il s’agit d’un faux positif. La probabilité $\epsilon$ d’une telle erreur est d’environ $(1-e^{\frac{-kn}m})^k$, où $k$ est le nombre de fonctions de hachage, $m$ est la taille du tableau et $n$ est le nombre d’élément déjà ajoutés dans la structure. Cette approximation est d’autant plus fiable que le rapport $\frac m n$ est faible.
La valeur de $k$ qui minimise le taux de faux positifs est $k=\frac m n \ln2$. En supposant que $k$ est cette valeur optimale et étant donné la probabilité de faux positifs $\epsilon$ et le nombre d’entrée dans la table $n$, la taille optimale est $m=-\frac{n \ln\epsilon}{(\ln2)^2}$.
Dans notre cas d’usage, il faudrait conserver une probabilité de faux positifs $\epsilon$ inférieure à 0.1%, afin de dissuader les attaques par force brute. Le nombre d’entrées dans la structure $n$ peut raisonnablement valoir 1000 pendant le développement, 1 millions en cas de succès du gestionnaire de mots de passe et 1 milliards en cas d’utilisation massive par de très nombreux utilisateurs.
| valeurs pour $\epsilon=10^{-4}$ | $n=10^3$ | $n=10^6$ | $n=10^9$ |
|---|---|---|---|
| $m$ taille en bits du tableau | 19200 | 19 200 000 | 19 200 000 000 |
| $k$ nombre de fonctions de hachage | 13.3 | 13.3 | 13.3 |
| $\log_2(m)$ longueur en bit des fonctions de hachage | 14.2 | 24.2 | 34.2 |
| taille du filtre de Bloom | 2.34 Ko | 2.29 Mo | 2.23 Go |
On observe une taille maximale de l’ordre de quelques Giga octets, ce qui est plus que raisonnable pour autant d’utilisateurs.
Redimensionnement du filtre de Bloom
Lorsque le nombre d’entrée dans le filtre de Bloom augmente au delà de ce qui est prévu, la probabilité d’un faux positif dépasse le seuil d’acceptabilité fixé. Il faut alors augmenter la taille du tableau utilisé par le filtre pouvoir stocker d’avantage d’utilisateurs sans augmenter la probabilité de faux positifs. Comme il est possible d’avoir un nombre conséquent d’entrées dans la table pour un espace relativement limité, il est raisonnable de penser que cette opération sera assez rare dans la vie du gestionnaire de mots de passe.
Lorsque cela se produit, le serveur doit conserver deux versions du filtre de Bloom pendant une durée assez longue de transition. Pendant toute cette durée de transition, lorsque le serveur reçoit un message de la part d’un client, il doit procéder aux étapes suivantes :
- si le client est enregistré dans le nouveau filtre de Bloom alors rien (le client a déjà été enregistré dans la nouvelle table, le message est accepté et placé en attente de livraison) ;
- sinon si le client est enregistré dans l’ancien filtre de Bloom alors le serveur l’enregistre également dans le nouveau (le message est accepté et placé en attente) ;
- sinon le client est challengé avant d’être ajouté au nouveau filtre de Bloom (c’est un nouveau client, voir séquence d’enregistrement).
La durée de transition n’a pas de valeur précise définie à l’avance. Elle doit être ajustée afin de permettre que le plus grand nombre d’utilisateurs puisse s’enregistrer sur les deux serveurs. Pour cela, il sera nécessaire de conserver en mémoire le nombre de clients présents dans chaque table, ainsi que pour la durée de transition, le nombre de clients importés depuis l’ancienne table vers la nouvelle via le point numéro 2 ci-dessus. Lorsqu’une proportion satisfaisante de clients ont été transférés vers la nouvelle table, la durée de transition peut prendre fin.
Les utilisateurs qui tenteront de communiquer avec le serveur après une période d’absence plus grande que la durée de transition seront inconnus du nouveau filtre de Bloom. Il leur sera alors demandé de s’enregistrer à nouveau auprès du serveur, en procédant à un challenge comme le décrit la séquence d’enregistrement. Si le client s’enregistre auprès du serveur avec la même clé publique que précédemment, il pourra conserver ses communications avec les autres appareils de manière transparente.
Découverte des clients
Comme le serveur n’enregistre aucune donnée sur les clients, il n’est pas possible pour un client de “découvrir” les autres appareils avec lesquels partager un coffre en passant le serveur sans avoir au préalable échangé des clés cryptographiques. Le terme découverte est pris dans le sens de la prise de connaissance des clés publiques des autres clients, ainsi que de quelques caractéristiques (nom affiché à l’utilisateur, etc.), il n’y a pas de notion d’adresse.
Les moyens de communication pour découvrir les clients sont nécessairement synchrones :
- Bluetooth : canal bidirectionnel, les deux appareils doivent le supporter
- QR Code : canal unidirectionnel, seul l’appareil destinataire doit posséder une caméra
- Stockage externe : canal unidirectionnel, les deux appareils doivent posséder des ports compatibles, l’utilisateur doit avoir un périphérique USB ou SD
- LAN : canal bidirectionnel, les deux appareils doivent être sur le même réseau
- ICE : canal bidirectionnel, pas de contrainte sur les appareils
Les canaux unidirectionnels peuvent être rendus bidirectionnels, soit en répétant le processus dans l’autre sens, soit plus simplement en passant par le serveur. Lorsqu’un appareil transmet sa clé publique à un autre via un canal unidirectionnel, ce dernier peut envoyer un message au serveur contenant sa propre clé publique avec pour destinataire le premier appareil. Celui-ci peut ensuite récupérer la clé publique de l’autre auprès du serveur. Ce message n’est pas chiffré de bout-en-bout entre les deux appareils mais n’a pas besoin de l’être, il n’est chiffré qu’entre les appareils et le serveur. Le serveur peut alors pratiquer une attaque de l’homme sur le côté (Man-on-the-Side ou MotS) et usurper l’identité de l’un des appareils auprès de l’autre. L’utilisateur sera alors amené à vérifier son numéro de sécurité sur les deux appareils suite à cet échange.
L’opération de découverte des clients est censée être synchrone. Lorsqu’un appareil envoie une clé publique à un autre via le serveur, le message correspondant sera stocké sur le serveur pendant une durée relativement courte, la date de péremption sera de l’ordre d’une dizaine de minutes. Au delà de ça, l’utilisateur devra de nouveau envoyer la clé depuis son appareil afin de la récupérer sur un autre autre. Plusieurs clés peuvent être envoyées de cette manière.
L’utilisateur doit donc relier ses appareils entre eux en plus de les enregistrer auprès du serveur. Chaque appareil doit découvrir chaque autre manuellement, il y a pour cela trois procédures :
-
méthode diffusion : chaque appareil envoie toutes les identités qu’il connait à tous les appareils qu’il ne connait pas encore, chaque appareil répond toutes les identités qu’il connait et que l’autre appareil ne connait pas
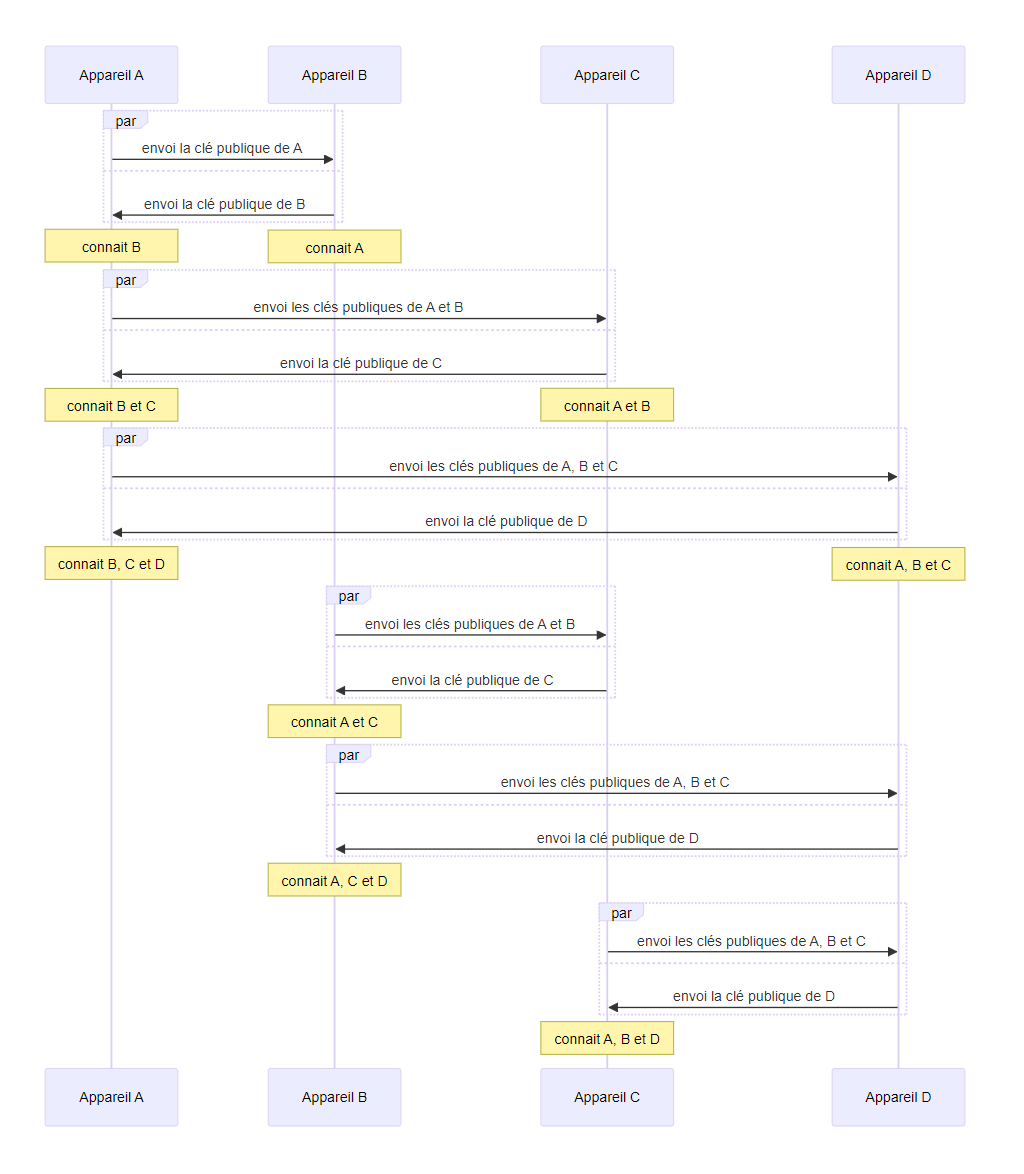
- point négatif : de nombreux messages sont inutiles
- point négatif : le très grand nombre d’échanges nécessaires, $n(n-1)$ pour $n$ appareils
- point négatif : les échanges doivent être bidirectionnels
- point positif : les échanges peuvent être réalisés dans n’importe quel ordre
-
méthode circulaire : le premier appareil envoie son identité au deuxième, le deuxième envoie son identité et celle du premier au troisième, etc., jusqu’au dernier qui envoie toutes les identités au premier
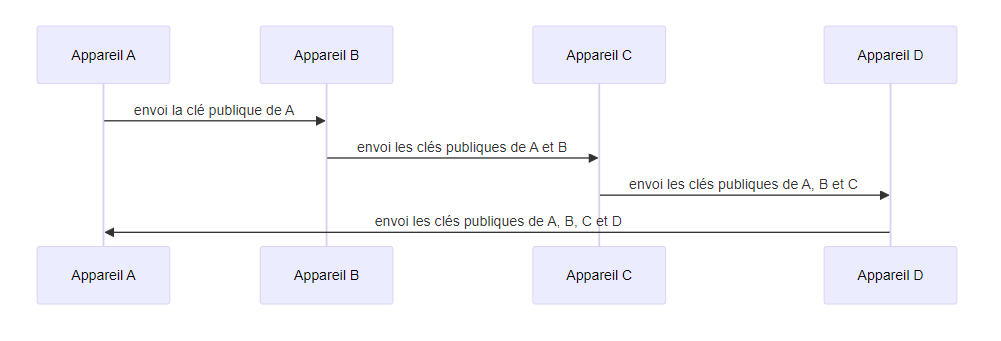
- point négatif : les échanges doivent être réalisés dans un ordre précis
- point positif : le faible nombre d’échanges nécessaires, $n$ pour $n$ appareils
- point positif : les échanges peuvent être unidirectionnels
-
méthode maître : dans un premier temps un appareil maître reçoit l’identité de chaque autre, ensuite le maître envoie toutes les identités à chacun
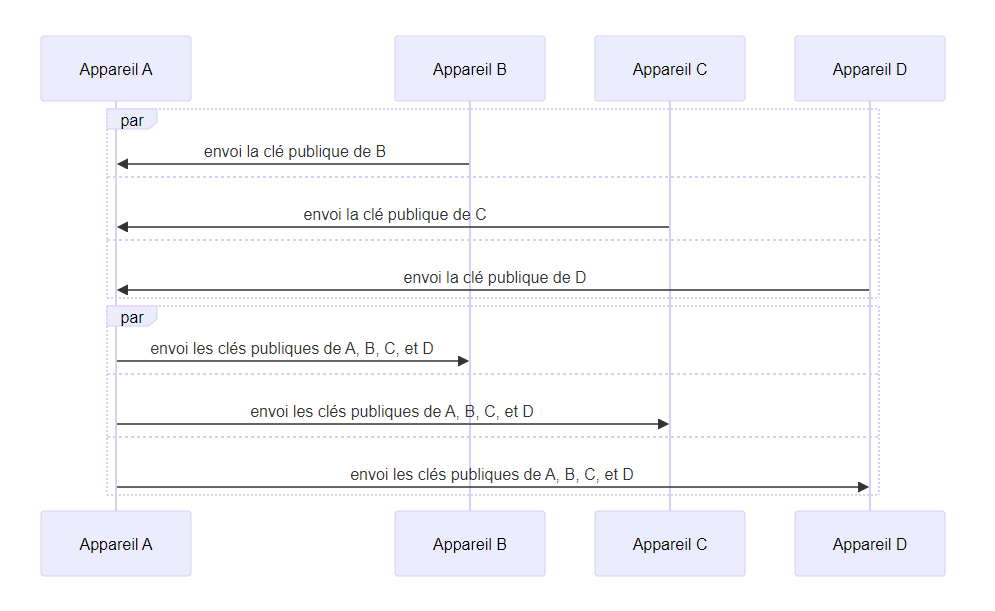
- point négatif : le nombre d’échanges nécessaires, $2(n-1)$ pour $n$ appareils
- point positif : les échanges peuvent être unidirectionnels
- point positif : les échanges peuvent être réalisés dans n’importe quel ordre
À noter que pour faire se découvrir deux appareils, l’utilisateur doit manipuler les deux en même temps, c’est donc une opération peu ergonomique. Pour minimiser le nombre transmissions à effectuer, la deuxième méthode est plus efficace, $n$ messages pour $n$ appareils contre $n(n-1)$ et $2(n-1)$. Mais la troisième méthode est plus pratique à utiliser car les échanges n’ont pas d’ordre précis et que le fonctionnement ne dépend pas du nombre d’appareils. Pour d’autres raisons, notamment la gestion des clients d’un coffre, il serait avantageux d’avoir recours à un appareil maître pour chaque coffre. Les clients pourront également supporter les autres méthodes qui pourront être réalisées entièrement ou en partie.
Afin d’assurer à l’utilisateur que tous ses clients ont connaissance les un des autres, le calcul d’un numéro de sécurité prendra en compte le nombre et l’identité des clients qui partagent un coffre. L’utilisateur peut facilement vérifier que tous les clients sont reliés et qu’aucune attaque n’a été effectuée en vérifiant que ce numéro de sécurité est identique sur chacun d’entre eux.
Communications
Les échanges entre les clients sont des messages contenants les modifications à apporter au coffre stocké sur les appareils. Le coffre est chiffré deux fois par deux clés différentes pour assurer que le déchiffrement ne soit possible qu’en connaissant du mot de passe maître et en utilisant un appareil ayant le droit d’accéder au coffre. Les messages chiffrés de bout en en bout sont transmis du client au serveur puis du serveur aux autres clients, chacune de ces communications est également chiffrée entre le client et le serveur, de sorte qu’un client ne puisse déchiffrer que le message qui lui est destiné.
Communication entre clients
Pour offrir plus de sécurité, les messages ne doivent pouvoir être déchiffrés que depuis un appareil dans le coffre, la connaissance du mot de passe maître n’est pas suffisante. Les messages sont chiffrés et déchiffrés grâce à un secret partagé entre tous les clients du coffre et dont l’utilisateur n’a pas besoin d’avoir connaissance.
Le mot de passe maître ne sert pas au chiffrement des données qui sont échangées entre les clients. Il ne sert qu’à chiffrer et déchiffrer l’espace mémoire sur chaque client. Le fonctionnement du chiffrement basé un mot de passe maître est bien connu : lorsque l’utilisateur entre son mot de passe maître celui-ci est haché grâce à une fonction de hachage cryptographie puis comparé au hachage stocké dans le client. Si les valeurs correspondent alors le mot de passe maître est correct, il est ensuite dérivé en clé de chiffrement symétrique grâce à une fonction de dérivation de clé (key derivation function, KDF), cette clé peut enfin être utilisée pour chiffrer et déchiffrer le coffre. C’est en déchiffrant cette mémoire que le client peut accéder à toutes ses informations sécurisés, comme sa clé privée, son identifiant d’enregistrement, en plus de ses secrets.
Création d’une clé partagée
La clé qui permet de s’assurer que le chiffrement et déchiffrement a lieu depuis un client ayant le droit d’accès au coffre nécessite de mettre en place un secret partagé entre tous ses clients. Si tous les clients ayant accès à un coffre donné possèdent un secret relatif au coffre, alors seul un client ayant le droit d’accéder au coffre pourra le déchiffrer, indépendamment de la connaissance de l’utilisateur du mot de passe maître.
Cas à deux appareils
La création d’un tel secret est trivial dans le cas où il n’y a que deux appareils : l’échange de clés Diffie-Hellman, compatible avec la cryptographie sur les courbes elliptiques, permet à deux partis de se mettre d’accord sur une valeur commune en un seul tour. Cela signifie que deux côtés peuvent échanger des informations publiquement et parvenir à un secret partagé qu’ils sont les seuls à connaître. Ce secret peut à son tour être dérivé en une clé symétrique que l’on nomme clé partagée ou clé de session. Cette procédure est largement utilisée sur Internet via HTTPS, car le calcul de la clé partagée et son utilisation symétrique sont des calculs bien plus faciles à effectuer qu’un chiffrement asymétrique.
Cependant, l’utilisation de l’échange de clés Diffie-Hellman n’est possible que s’il n’y a que deux partis. Il n’existe pas de solution élégante largement reconnue dans le cas d’usage où davantages de clients souhaiteraient se mettre d’accord sur une valeur secrète. Le parti pris du protocole Signal est alors de réaliser un chiffrement pair-à-pair : lorsqu’un message est envoyé dans un groupe, il est en réalité chiffré de manière indépendante pour chaque destinataire puis chaque message ainsi chiffré est transmis au serveur, qui délivrera alors chaque version chiffrée au destinataire correspondant. C’est pour cette raison que lorsqu’un nouvel arrivant entre dans une conversation chiffrée de bout en bout, il n’a pas accès aux messages précédents.
Ce fonctionnement implique qu’un message envoyé au serveur en attente de livraison doit être stocké autant de fois que le message possède de destinataire. S’il était possible de créer un secret partagé entre tous les clients, il n’y aura qu’un seul message à stocker du côté du serveur, dans l’attente de la livraison à chacun des clients. Or la charge de travail du serveur est un sujet primordial afin de mutualiser les coûts de fonctionnement de gestionnaire de mots de passe.
Cas à trois appareils
Pour une utilisation sur trois appareils, il est possible d’utiliser la cryptographie à base de couplages qui repose sur l’utilisation de plusieurs courbes elliptiques ainsi qu’une fonction nommée couplage sur ces courbes. En particulier, les couplages utilisés sont bilinéaires, ce qui permet à chaque utilisateur de manipuler les deux clés publiques des autres comme une seule.
Ce domaine fait l’objet de recherches académiques, mais il n’existe pas encore d’application largement utilisée comme c’est le cas pour l’échange de clés Diffie-Hellman sur les courbes elliptiques. Pour plus d’informations, voir l’étude sur les échanges de clés multipartites Diffie-Hellman.
Cas à $N$ appareils
En l’état actuel des recherches scientifiques, la cryptographie à base de couplage n’est pas encore assez performante pour permettre à quatre appareils ou plus d’échanger une clé. Pour cela, il faudrait être en mesure de trouver des couplages avec pour ensemble de départ $N$ courbes elliptiques, mais il n’existe a priori pas de méthode pour trouver ces couplages.
Il n’est pas sécurisé d’utiliser des méthodes d’échange de clé en plusieurs tours, comme décrit dans l’étude sur les échanges de clés multipartites Diffie-Hellman, car on souhaite conserver un calcul de la clé partagée en un seul tour, en connaissant la clé privée d’un appareil et les clés publiques des autres, afin de pouvoir implémenter le Double Ratchet du protocole Signal. En plus, l’obligation de créer une clé partagée manuellement de façon synchrone sur tous ses appareils crée un manque d’ergonomie.
Dans le cas où un coffre n’est partagé qu’entre deux à trois appareils, il n’y a pas de difficulté concernant la création d’une clé partagée. Pour quatre appareils ou plus, plusieurs options sont à envisager :
- le nombre maximal d’appareils peut être limité à trois : l’utilisateur sera invité à créer différents coffres pour différents usages afin qu’aucun ne dépasse trois appareils
- l’une des méthodes à plusieurs tours peut être implémentée : l’utilisateur devra réaliser un nombre important d’échanges entre tous ses appareils et il sera mis en garde d’un risque de sécurité (la post compromise security n’est pas assurée, si un échange venait à être décrypté par un attaquant, tous les échanges suivants seraient compromis jusqu’à la création manuelle d’une nouvelle clé partagée)
- le service de nombreux appareils peut être payant : l’utilisateur pourra ajouter autant d’appareils qu’il souhaite, les messages seront chiffrés deux à deux ou trois à trois et stockés plusieurs fois dans le serveur mais ce service sera facturé en raison de l’utilisation conséquente des ressources du serveur
- si la cryptographie à base de couplage permet une généralisation à $N$ appareils : un ensemble de couplages pourra être prédéfini pour $N$ allant de 3 à une valeur maximale, qui serait le nombre maximal d’appareils pour un coffre
L’option à favoriser pour l’implémentation du gestionnaire de mots de passe n’est pas encore sélectionnée.
Ajout d’un nouveau client
Lorsque l’utilisateur souhaite ajouter un nouvel appareil à son coffre, après l’avoir enregistré auprès du serveur, il doit annoncer l’appareil entrant à tous les appareils qui partagent déjà le coffre. L’étape de découverte du nouveau client se fait selon les méthodes décrites plus tôt : méthode diffusion, méthode circulaire ou méthode maître. L’appareil entrant doit envoyer son identité à chacun des autres appareils, et l’un des appareils déjà présents doit envoyer les identités de tous les appareils déjà présents à l’appareil entrant. Si l’appareil entrant a une difficulté à contacter l’un des autres appareils, son identité peut être retransmise par un appareil qui la possède déjà. Cette opération doit être faite manuellement par l’utilisateur de façon synchrone entre les appareils.
Lorsqu’un nouvel appareil est ajouté au coffre, la clé partagée devient obsolète, une nouvelle clé partagée est calculée grâce aux méthodes décrites ci-dessus : Diffie-Hellman sur les courbes elliptiques pour deux appareils, Diffie-Hellman à base de couplage pour trois appareils ou autre.
Format des messages
Les messages échangés entre les clients contiennent des mises à jour de fichiers qui décrivent les secrets stockés dans le coffre. Un fichier de secret contient la description d’un secret détenu dans le coffre, ce peut être un mot de passe, un secret à conserver ou même une note personnelle. Le format des fichiers de secret n’est pas encore précisément spécifié, mais il peut s’agir pour l’exemple d’un fichier au format JSON avec un champ obligatoire secret qui contiendrait un mot de passe ou un code secret, ainsi que des champs optionnels comme username, url ou tag.
En plus des éléments contextuels (nouvelle clé publique, horodatage, liste de destinataires), un message envoyé par un client contient la mise à jour de tous les fichiers de secret ajoutés ou modifiés, à la manière d’une différence de version avec un gestionnaire comme Git.
Double Ratchet
Les clients s’échangent des messages chiffrés de bout en bout grâce à la clé partagée. Si la clé partagée ne change jamais de valeur, cela signifie que si par malheur pendant toute la durée du coffre de mots de passe un attaquant parvenait à casser la clé partagée, alors il pourrait déchiffrer l’intégralité des messages passés et à venir. Le problème ne se pose pas avec des communications sur Internet par exemple, car les échanges s’étalent sur une durée très courte. Pour un gestionnaire de mots de passe, les échanges peuvent durer longtemps, potentiellement la durée de vie de l’utilisateur, alors que le nombre de mots de passe stockés fait augmenter l’intérêt de casser le coffre.
Il faudrait donc changer la clé partagée régulièrement. La première solution serait d’ajouter une date de péremption sur la clé. La clé serait utilisée pour chiffrer les messages jusqu’à cette date, à partir de ce moment-là tout appareil qui a vérifié auprès du serveur qu’il n’a plus de message en attente peut supprimer la clé périmée. Mais lorsqu’un appareil est le premier à se rendre compte que la clé est périmée, il doit envoyer une demande de mise à jour de la clé publique à tous les autres appareils. Une fois que tous les appareils du coffre ont répondu, chaque appareil peut récupérer les clés publiques des autres et calculer la nouvelle clé partagée. En attendant que cela ne soit fait, aucun appareil ne peut envoyer de nouveau message. Cette mise-à-jour devrait donc être faite de façon synchrone.
Pour changer de clé partagée automatiquement à chaque message envoyé, les clients utiliseront une fonction de dérivation de clé (key derivation function ou KDF) qui fonctionne comme un hachage pour fournir des clés de chiffrement en sortie. L’entrée d’une fonction de dérivation de clé peut notamment être une clé symétrique, ce qui serait le cas ici : lors de l’envoi du premier message dans le coffre, la clé partagée initiale est dérivée pour obtenir la première clé de chiffrement. L’appareil qui émet le message et ceux qui le reçoivent partent de la même clé partagée initiale et utilisent la même fonction de dérivation, tout le monde est alors capable de déchiffrer le message avec la même clé, sans s’être partagé d’informations supplémentaires.
Cette fonction de dérivation de clé fonctionne comme un roue à cliquet ou roue à rocher (ratchet), c’est-à-dire qu’elle ne permet d’aller que dans un sens, il n’est pas possible de remonter pour déterminer les clés qui ont été utilisées précédemment. Ainsi, si un attaquant stockait l’intégralité des messages chiffrés d’un coffre et que par chance il parvenait à casser le chiffrement de l’un d’entre eux, il ne serait pas en mesure de déchiffrer tous les messages précédents, c’est la forward secrecy.
En revanche à partir de là, en connaissant la fonction de dérivation de clé et une clé servant à déchiffrer un message, l’attaquant est en mesure de déterminer la totalité des messages qui suivront. Pour palier à cette faille, les clients utilisent un ratchet supplémentaire de Diffie-Hellman. À chaque message envoyé, le client inscrit à l’intérieur une nouvelle clé publique pour lui-même, il peut désormais jeter son ancienne clé publique et la clé privée associée. Les clients qui reçoivent ce message peuvent le déchiffrer grâce à la clé partagée en cours, puis mettent à jour l’identité du client qui a émis le message : comme sa clé publique a changé, grâce à l’échange de clé Diffie-Hellman, une nouvelle clé partagée initiale est déterminée, qui sera utilisée comme point d’entrée pour l’autre ratchet. De cette manière, l’attaquant qui parviendrait à déchiffrer un message n’aurait connaissance que de la nouvelle clé publique du client qui a émis le message. Même s’il connaissait les clés publiques de tous les autres appareils, il ne pourrait pas déterminer la prochaine clé partagée, il lui faudrait la casser de nouveau. Cette propriété est la post-compromise security.
C’est pour cette raison qu’il est important d’avoir une méthode équivalente à Diffie-Hellman qui permette à plusieurs partis de calculer une clé partagée en un seul tour, afin de pouvoir la mettre à jour à chaque message envoyé. Sans cette méthode, il faudrait chiffrer les messages de façon pair-à-pair et les stocker autant de fois sur le serveur (c’est la solution optée par le protocole Signal pour les conversations de groupe) ou bien obliger l’utilisateur à réinitialiser régulièrement la clé partagée et renoncer à la post-compromise security pendant l’utilisation de chaque clé.
De plus, il serait possible d’ajouter deux ratchets en sortie du premier, un pour l’émission de message et un pour la réception. Dans une conversation pair-à-pair, les ratchets doivent être synchronisés de telle façon que le ratchet d’émission de l’un corresponde toujours au ratchet de réception de l’autre et réciproquement. Lorsque l’un des pairs envoie plusieurs messages d’affilée, il ne met à jour sa clé publique que lors du premier envoi de message, et pour chacun des messages suivants, il n’incrémente que le ratchet d’émission. L’émetteur précise dans chaque message son numéro pour que le récepteur puisse les remettre dans l’ordre si besoin. Chaque message est chiffré avec une clé différente. De cette manière, l’autre pair peut déchiffrer chaque message indépendamment en faisant tourner son ratchet de réception autant de fois que le nombre indiqué dans le message. Si les messages n’arrivent pas dans l’ordre, il peut tout de même déchiffrer les premiers arrivés et conserver l’état initial de son ratchet de réception pour déchiffrer les autres messages quand ils arriveront. Au sein d’une suite de message, la clé publique de l’émetteur n’est pas réinitialisée, donc la post-compromise security n’est pas assurée, mais cela ne concerne en général que peu de messages et ne représente pas un si grand risque, la sécurité étant rétablie dès que l’autre pair envoie un nouveau message.
Dans le cas d’un gestionnaire de mots de passe avec plusieurs appareils, il n’est pas possible d’avoir recours à ces deux ratchets, car le ratchet de réception pour les uns ne sera pas forcément le ratchet de réception pour les autres. Cela ne devrait pas trop poser problème dans la mesure où chaque client reçoit du serveur la pile des messages en attente dans l’ordre dans lequel ils ont été reçu. Lorsqu’un client reçoit plusieurs messages en attente, il déchiffre le premier grâce à sa version actuelle de la clé partagée, met à jour la clé partagée avec la nouvelle clé publique de l’émetteur du message, déchiffre le deuxième message, ainsi de suite. Si un même client envoie plusieurs messages d’affilée, il doit mettre à jour sa clé publique dans chacun d’entre eux. Les clients qui récupèrerent les messages devront les déchiffrer dans l’ordre.
Si le problème de l’ordre de réception des messages est récurrent, il est possible d’ajouter non pas deux ratchets comme Signal, mais autant de ratchets qu’il y a d’appareils dans le coffre, chacun étant le ratchet d’émission d’un seul appareil.
Si deux clients venaient à envoyer deux messages simultanément, c’est-à-dire qu’un premier A envoie un message et qu’un deuxième B en envoyait un aussi avant de récupérer le premier, alors celui-ci chiffrerait son message à partir d’une clé qui ne pourrait pas être reconstituée par n’importe quel autre client du coffre, car la clé publique de A aura changé entre le moment où B envoie son message et le moment où les autres clients reçoivent chaque message. Le premier message étant reçu en premier, pour chaque client autre que B, la clé partagée ne sera pas compatible. De son point de vue, B ne peut pas se rendre compte de la situation car il recevra le message de A après avoir envoyé le sien. Il ne se rendra compte qu’il est exclu du coffre que lorsqu’il recevra un nouveau message qu’il ne sera pas en mesure de déchiffrer. Un appareil C envoie un message chiffré par la nouvelle clé partagée qui comprend la nouvelle clé publique de A mais pas la nouvelle clé publique de B (puisqu’au moment de recevoir le message qui la contenait, C ne pouvait pas le déchiffrer car il avait déjà mis à jour la clé partagée).
Pour éviter qu’un tel évènement ne se produise, un client doit systématiquement envoyer une demande de récupération des messages en attente avant d’envoyer un nouveau message. En pratique, il peut même envoyer le nouveau message en même temps que la demande de récupération des messages en attente, d’une manière similaire au piggybacking dans un protocole de transport de données. Le serveur doit refuser d’ajouter un pile un message qui provient d’un client qui a encore des messages en attente d’être récupérés. Les clients peuvent également ajouter un horodatage à l’intérieur des messages qu’ils envoient, afin de vérifier qu’aucun message antérieur ne soit reçu ultérieurement. Cet horodatage est différent de celui utilisé par le serveur pour calculer la date de péremption d’un message, le but étant d’être précis afin de détecter les inversions de messages envoyés quasiment simultanément.
Communication avec le serveur
Pour s’échanger des messages, les clients doivent communiquer avec le serveur de manière sécurisée. Les messages sont d’abord transmis au serveur pour y être stockés, jusqu’à ce qu’ils aient été délivrés à tous leurs destinataires.
Stockage des messages
Afin de retrouver rapidement les messages en attente pour un client donné, le serveur utilisera une table de hachage. Cette structure de données permet de stocker des données reliées à des clés en entrée. Dans notre cas, les clés seront les identifiants d’enregistrement des clients stockées dans le filtre de Bloom. D’une manière similaire au filtre, en calculant le résultat d’une fonction de hachage sur la clé, on obtient l’adresse d’une case de la table, cette case contient la valeur associée à la clé. Contrairement à une liste classique, il n’est pas nécessaire de parcourir la structure dans l’ordre pour trouver la valeur d’une clé. Si la valeur est vide, c’est que la clé ne contient pas de valeur associée.
Afin de garantir l’anonymat des échanges à travers le serveur, les destinataires des messages sont donnés au serveur sous forme de hachage cryptographique d’identifiant d’enregistrement. Au sein d’un coffre, chaque appareil connait l’identifiant d’enregistrement de tous les autres et peut calculer les hachages. Le serveur peut vérifier que le hachage correspond à un identifiant d’enregistrement connu grâce au filtre de Bloom sans connaître l’identité de l’utilisateur.
Fonctionnement de la table de hachage
Soit $T$ une table de taille $m$ et $h$ une fonction de hachage cryptographique de taille $\log_2(m)$ de sorte que pour toute clé $c$, $h(c)$ soit compris entre 1 et $m$. Les cases de la table sont de taille identique $k$. La taille de la table est $m\times k$.
Pour ajouter une valeur $v$ associée à une clé $c$ dans la table, il faut calculer le résultat de la fonction de hachage sur la clé, et affecter la valeur $v$ à la case correspondante : $T[h(c)]=v$. Dans notre cas d’usage, il faut également que la valeur associée à une clé puisse être supprimée, auquel cas on nullifie la case. Pour rechercher une valeur à partir d’une clé, il suffit de faire le même calcul et de récupérer la valeur stockée à la case d’indice $h(c)$.
En raison de l’utilisation d’une fonction de hachage cryptographique, comme pour le filtre de Bloom, il est possible d’avoir des collisions, c’est-à-dire que deux identifiants d’enregistrement soient associées via la fonction de hachage à la même case dans la table. Pour contourner ce problème, il existe deux solutions :
- l’adressage ouvert : la nouvelle valeur est stockée à une autre endroit dans la table, la méthode pour trouver ce nouvel endroit s’appelle un sondage, qui peut être :
- linéaire : $h_{i+1}(c) = h_i(c)+A, A\in\mathbb N$
- quadratique : $h_i(c) = (h(c)+(-1)^{i+1}.\lceil\frac i2\rceil^2)\bmod m$
- en double hachage : $h_{i+1}(c) = h(h_i(c))$
- le chaînage : les valeurs dans la table sont des listes chaînées, la nouvelle valeur est ajoutée en fin de liste
L’adressage ouvert ne permet pas suppression des valeurs après ajout, sinon lors d’une recherche de valeur il serait impossible de distinguer la suppression d’une valeur collision et l’absence de valeur. L’utilisation de liste chaînée permet la suppression dans la table.
Or la recherche dans une liste est moins efficace que dans une table de hachage. Si la table contient trop de collisions, les listes chaînées de chaque case de la table s’allongent et la recherche prend plus de temps. Tant que la répartition est uniforme et que la moyenne du nombre de collisions est relativement basse, ce n’est pas un problème. Le facteur de charge $\frac nm$ est un indicateur de la probabilité de collision d’une nouvelle entrée, si ce facteur est proche ou supérieur à 1, les nouvelles collisions sont systématiques ou presque, alors il faut agrandir la table.
| $k=32\ bits$ et $n=10^6$ | $\frac nm = 0.1$ | $\frac nm = 0.25$ | $\frac nm = 0.5$ | $\frac nm = 0.80$ | $\frac nm = 1$ |
|---|---|---|---|---|---|
| $\log_2(m)$ longueur en bit de la fonction de hachage | 13 | 12 | 11 | 10 | 10 |
| $m\times k$ taille de la table de hachage | 38 Mo | 15 Mo | 8 Mo | 5 Mo | 4 Mo |
Ajout et recherche de message
Chaque client peut avoir plusieurs messages en attente, la liste chaînée d’une case de la table contiendra elle-même les listes de messages en attente pour chaque clé à laquelle est associée la case. Une liste de message fonctionnera comme une pile, elle pourra augmenter lorsque de nouveaux messages en attente arrivent, ou bien être totalement vidée lorsque le client récupère ses messages.
Comme l’utilisation d’espace mémoire est restreinte, les messages seront en réalité stockés librement, avec leur liste de destinataires, en dehors de la table de hachage. Les valeurs dans les listes de messages indexées dans les listes chaînées de la table de hachage seront des pointeurs vers l’adresse des messages correspondants. Un pointeur sera dupliqué pour chaque destinataire du message. Les valeurs étant des pointeurs, la taille des cases variera entre 32 et 64 bits selon le système.
Les valeurs de la table de hachage seront donc des doubles listes chaînées afin de mémoriser des piles de messages en attente et d’éviter les collisions dans la table de hachage. Voici un exemple d’implémentation en C :
typedef struct message message;
struct message
{
void* message;
message* next;
};
typedef struct stack stack;
struct stack
{
void* messages;
void* register_id;
stack* next;
};
typedef stack* table_cell;
void table[] = malloc(m*sizeof(table_cell));
Lorsque la table de hachage doit être agrandie, comme pour le filtre de Bloom, les deux tables sont conservées pendant la durée de la transition. À noter cette fois-ci que, passé la date de péremption des messages, l’ancienne table pourrait être supprimée car tous les messages vers lesquels elle pointerait auront été supprimés, auquel cas le serveur ne pourra pas dire aux clients si l’utilisateur doit effectuer une vérification manuelle. Enfin, il est possible d’utiliser des fonctions de hachage qui permettent de doubler la taille de la table en conservant l’association des clés et des valeurs déjà enregistrées.
Lorsque le serveur reçoit un message à délivrer, il l’enregistre dans la liste de tous les messages en attente, puis il ajoute l’adresse du message dans la table de hachage pour chaque destinataire.
Fonction ajout_message(message)
Pour dest parmi message.destinataires
Si test_filtre(dest) alors
ajout_hashtable(dest, &message)
Fin Si
Fin Pour
Fin Fonction
Lorsque le serveur reçoit une requête d’envoi de messages en attente, il récupère la liste des messages en attente dans la table de hachage et les transmet au client. La liste des messages récupérée peut être vide, auquel cas le client n’a pas de message en attente. Si elle n’est pas vide, pour chaque message dans la liste, le client est retiré de la liste des destinataires. Si la liste de destinataires est vide après cela, le message est supprimé. Si l’un message a été supprimé avant récupération par le client à cause de la date de péremption, le serveur précise au client que l’utilisateur doit réaliser une synchronisation manuelle à partir d’un appareil à jour.
Fonction recherche_messages(cle)
messages = recherche_hashtable(cle)
Si messages n'est pas vide alors
Pour message dans messages
Si message est accessible alors
retirer(message.destinataires, cle)
Si message.destinataires est vide
supprimer(message)
Fin Si
Sinon
nouveau_message("Synchronisation manuelle requise")
Fin Si
Fin Pour
Fin Si
Retourner messages
Fin Fonction
À intervalle régulier, le serveur va vérifier la date de péremption de chaque message en attente. Pour cela, le serveur conserve également une liste des pointeurs vers les messages. Lors de ce passage, si un pointeur pointe vers un message supprimé, c’est que celui-ci a déjà été délivré à chacun de ses destinataires, le pointeur dans la liste des messages en attente peut être supprimé. À l’inverse, si un message est arrivé à péremption, il est supprimé et le pointeur associé dans la liste de messages en attente peut être supprimé également. Ce message devait encore être délivré à au moins un destinataire, lorsque celui-ci viendra chercher la liste des messages en attente pour lui, le serveur trouvera un pointeur pointant vers un message supprimé, il pourra supprimer ce pointeur et devra préciser au client qu’il lui manque un message, pour que l’utilisateur puisse procéder à une synchronisation manuellement entre ses appareils.
Sécurité sur la liste de messages en attente
Afin de provoquer un déni de service du serveur (Deny of Service ou DoS), un attaquant pourrait essayer de surcharger la liste des messages en attente jusqu’à ce que le serveur ne soit plus en mesure de prendre en charge de nouveaux messages d’utilisateurs légitimes.
Pour se protéger, lorsqu’il recevra un message, le serveur vérifiera dans la liste des messages en attente que ce client n’ait pas déjà dépassé une valeur maximale $l$ de messages envoyés. Cette mesure permet également dans une certaine mesure de lutter contre l’encombrement causé par un utilisateur qui enverrait toujours des messages depuis le même client sans les récupérer depuis ses autres clients. Une fois que le client a atteint la limite $l$ de messages en liste d’attente, pour chaque nouvelle tentative, l’utilisateur sera alerté par le serveur qu’il doit décharger manuellement le serveur depuis ses autres appareils ou attendre la date de péremption des messages en attente avant d’en envoyer de nouveaux. Si le client persiste à envoyer de nouveaux messages, à partir d’une valeur limite $l’$, le hachage de l’identifiant d’enregistrement du client est ajouté à un filtre de Bloom de liste noire. À l’avenir, tout message émis par ce client ou ayant ce client parmi ses destinataires sera systématiquement rejeté. À cause du fonctionnement du filtre de Bloom, l’ajout d’un client en liste noire est définitif. Lorsqu’un client est ajouté en liste noire, tous les messages en attente desquels il est émetteur ou destinataire sont supprimés.
Dans le cas où l’attaquant tenterait de surcharger le serveur depuis tous ces appareils, le serveur vérifiera également si le client qui a émis ce message ou les destinataires de ce message sont également les destinataires d’autres messages en liste d’attente. Si le nombre de messages en attente pour un coffre atteint une limite $L$, tout nouveau message qui sera envoyé depuis ou vers un client du coffre sera refusé par le serveur. Le serveur n’ayant pas de moyen de connaître le nombre de clients dans un coffre, la valeur de $L$ est fixe indépendamment du nombre de clients dans le coffre. Cette protection permet tout de même l’ajout de $\frac{l\times N}2$ messages en liste d’attente pour un coffre contenant $N$ appareils, l’attaquant pouvant limiter volontairement le nombre de destinataires de chaque message à un. Le serveur refusera tout message ayant au moins un destinataire non enregistré.
L’attaquant peut tenter de surcharger la pile depuis différents coffres, un client ne pouvant être mis sur liste noire que pour un coffre à la fois. Les clients possèderont donc une limite au nombre de coffres simultanés auxquels ils peuvent appartenir. Cette limite sera suffisamment élevée pour permettre une utilisation standard du gestionnaire de mots de passe par les utilisateurs bienveillants, probablement inférieure à dix. Cette mesure est uniquement logicielle du côté des clients, si un utilisateur malveillant utilise un client d’une autre implémentation, il est possible qu’il puisse prendre par à autant de coffres qu’il souhaite.
Pour quel le serveur puisse limiter le nombre de coffres par utilisateur, il faudrait que celui-ci maintienne une table de hachage basé sur le hachage de l’identifiant de l’utilisateur et le hachage de l’identifiant du coffre. Lorsqu’un client souhaite être enregistré dans le filtre de Bloom, le serveur vérifie dans cette table de hachage que le nombre de clients de cet utilisateur pour ce coffre ne dépasse pas une limite $L’$. Cette limite doit évoluer avec le temps, car les utilisateurs risquent d’enregistrer régulièrement de nouveaux clients, lors du renouvellement de leurs appareils, mais il n’est pas possible de vérifier qu’ils aient effectivement perdu ou supprimé leur clé publique, et il n’est pas non plus possible de retirer un enregistrement d’un filtre de Bloom. Cette solution impliquerait également que le serveur possède la connaissance du nombre de clients par coffre pour chaque utilisateur au moment où celui-ci enregistre un nouvel appareil (à ce moment, l’identifiant utilisateur est envoyé sans hachage pour procéder au challenge).
Ces sécurités permettent de prévenir un attaquant qui utiliserait des clients authentifiés pour provoquer un déni de service. Un attaquant qui tenterait d’envoyer des messages à partir d’un hachage d’identifiant d’enregistrement qui n’existe pas, en utilisant des collisions dans le filtre de Bloom, serait obliger d’utiliser la force brute pour trouver une clé qui fonctionne. La probabilité $(1-e^{\frac{-kn}m})^k$ que le filtre de Bloom renvoie un test de présence positif sur une valeur qui n’est pas présente dans le filtre dépend du paramètre $k$ qui est dimensionné pour avoir le taux de faux positifs souhaité. Si les attaquants parviennent à trouver régulièrement des clés qui sont acceptées par le serveur, il faut redimensionner le filtre de Bloom avec une valeur de $k$ plus adaptée.
Si par hasard un attaquant parvenait à trouver un hachage d’identifiant d’enregistrement qui soit effectivement enregistré, alors le client légitime correspondant à cette clé sera bloqué. L’utilisateur légitime aura la possibilité de réinitialiser son client, il devra alors manuellement ajouter à nouveau le client dans le coffre. Cette opération devrait être extrêmement rare, un attaquant ne pouvant pas savoir si un hachage trouvé par force brute et accepté par le filtre serait un faux-positif ou une valeur qui existe bel et bien.
Une fois le serveur dans un environnement de production, pour éviter que les attaquants ne puissent tester des hachages par force brute, le serveur ne précisera pas lors du dépôt d’un message si celui-ci a été accepté ou refusé à cause d’un client non enregistré, que ce soit l’émetteur ou un destinataire. Toute autre motif de refus de message qui n’entraîne pas de risque de sécurité doit faire l’objet d’une réponse spécifique.
Si un attaquant parvient à usurper plusieurs hachages acceptés par le filtre de Bloom, qu’ils soient trouvés par force brut ou en infectant des appareils d’utilisateur légitimes, que ce soient des faux-positifs ou non, si l’attaquant utilisait tous ces hachages pour provoquer une attaque par déni de service distribué (Distributed Deny of Service ou DDoS), c’est-à-dire que de nombreux clients procèdent à des attaques par déni de service en même temps, le serveur pourrait détecter cette activité anormale et se mettre dans un mode sécurisé, mode dans lequel il n’accepterait plus de nouveaux messages entrant, et attendrait que les messages en liste d’attente arrivent à péremption, quitte à avancer cette date de péremption en cas d’attaque. S’il le peut, le serveur pourra indiquer aux clients qui tentent d’envoyer des messages qu’une attaque est en cours et que les utilisateurs doivent réessayer ultérieurement. L’attaque provoquerait alors une indisponibilité de service le temps de l’attaque et jusqu’à la date de péremption des attaques, mais le serveur pourra être en mesure d’indiquer aux utilisateurs ultérieurs que, étant donné qu’une attaque a eu lieu, il est possible que des messages ait été supprimés par le serveur et doivent être synchronisés manuellement.
Chiffrement client-serveur
En plus du chiffrement de bout en bout des messages entre les clients, toutes les communications entre un client et le serveur sont également chiffrées. De cette manière, si deux clients appartiennent au même coffre, l’un ne peut pas épier les conversations de l’autre avec le serveur. Plus exactement, les informations échangées entre le client et le serveur sont chiffrées, comme les messages envoyés et récupérés ou la liste des clients dans un coffre lors de la découverte par exemple.
Pour chiffrer leurs communications, le client et le serveur doivent utiliser la même clé symétrique, mais ils doivent la changer entre chaque échange. Comme le serveur doit stocker le minimum d’informations possible, il ne peut pas garder en mémoire la clé publique de chaque client, il n’est alors pas possible d’utiliser un Double Ratchet comme pour les communications entre clients. Le client et le serveur vont alors procéder à un échange de clé Diffie-Hellman standard comme utilisé sur Internet via HTTPS notamment.
Le client qui souhaite initier une communication récupère le certificat du serveur. Ce certificat peut être vérifié via une infrastructure à clés publiques (Public Key infrastructure ou PKI) qui est indépendante du gestionnaire de mots de passe. Un certificat fonctionne grâce à la signature en cascade par d’autres certificats, en remontant jusqu’à un certificat racine qui connu à l’avance. Si le certificat racine est reconnu et qu’il a signé un certificat qui lui-même signe un certificat, ainsi de suite jusqu’au serveur, alors un client est en mesure d’assurer que la clé publique contenue dans le certificat est correcte. Cette vérification se fait sous condition d’intégrité du certificat racine dans la mémoire du client. Le serveur pourra avoir un certificat X.509 qui est le format le plus utilisé et il renouvellera son certificat régulièrement.
Une fois que le client a récupéré la clé publique du serveur grâce au certificat, il génère une clé publique éphémère qu’il transmet au serveur en même temps que le hachage de son identifiant d’enregistrement chiffré avec la clé symétrique calculée à partir de la clé publique du serveur et la clé privée éphémère associée à la clé transmise au serveur. À réception, le serveur peut calculer la même clé symétrique grâce à sa clé privée et la clé publique éphémère du client, ce qui lui permet de déchiffrer le hachage de l’identifiant d’enregistrement du client. Si après vérification dans le filtre de Bloom le hachage est reconnu, alors le serveur procéder au traitement de la requête du client. La requête du client peut être transmise dans le même message qui contient la clé publique éphémère et le hachage chiffré de l’identifiant d’enregistrement. La clé symétrique ne change pas pendant toute la durée d’un échange et elle est réinitialisée lors du prochain échange.
Le client ne doit jamais utiliser la clé publique qui fait partie de son identifiant d’enregistrement comme clé publique éphémère pour créer une clé symétrique avec le serveur. La clé publique de l’identifiant d’enregistrement ne doit pas être divulguée, sous peine d’être usurpée par des attaquants. Le client dont la clé a été divulguée risquerait alors de se retrouver ajouté à la liste noire des clients.
En pratique, le chiffrement entre le client et le serveur sera réalisé par le protocole TLS (Transport Layer Security) qui largement utilisé sur Internet via HTTPS. Ce protocole permet d’assurer l’authentification du client et la confidentialité et l’intégrité des données échangées.
Comme le serveur n’enregistre pas les clés publiques, la serveur n’a pas la garantie de l’authenticité du client, il ne se base pour ceci que sur le test de présence dans le filtre de Bloom du hachage de l’identifiant d’enregistrement du client.